
Constant Context Architecture
Building for the LLM Era

TL;DR: Constant Context Architecture (CCA) solves the problem of working with large codebases using LLMs. The formal guarantee is simple: if modules have bounded size (≤ Smax), interfaces (≤ Imax), and dependencies (≤ d), then modifying any module requires context C = Smax + d×Imax + Gmax ≤ LLM's context window, regardless of total codebase size. This makes gathering the necessary context for LLM code modifications a bounded operation—any change to any module in an arbitrarily large software project will always fit in an LLM's context window if it conforms to CCA. As AI-assisted development becomes increasingly common, this architecture ensures both humans and AI can effectively maintain codebases at any scale.
Software architecture is at a pivotal juncture. After decades of optimizing for human understanding, we now face a profound inversion: code is increasingly written, maintained, and extended by artificial agents with different cognitive constraints than ours. This is no longer speculative. AI-based coding assistants have reached significant adoption across major enterprises, reshaping our development practices in real time.
The shift is well illustrated by the growing use of AI coding assistants across the industry. While exact usage metrics vary widely by team and organization, these tools are rapidly becoming integral to software development workflows. The trend clearly indicates that AI-augmented programming isn't coming—it's already here, unevenly distributed among those prepared to exploit it architecturally.
Ironically, as models like GPT-4 and Claude become more powerful, their context limitations remain conspicuous. Even with context windows ranging from 100K to 1M+ tokens, it's neither practical nor efficient to feed an entire monolithic codebase to an LLM. This is partly due to computational overhead, bandwidth constraints, and the well-documented "lost in the middle" effect, wherein LLMs often fail to effectively leverage very large prompts. Despite incremental improvements, context limitations will persist—and so will their performance trade-offs.
In response, I propose "Constant Context Architecture" (CCA). It ensures any change within a large-scale system remains comprehensible to an LLM with a fixed, bounded context window. This framework builds on decades of established software design principles—information hiding, domain-driven bounded contexts, SOLID—but now with an explicit focus on enabling AI-driven development at scale.
Key Principles at a Glance
Here are the core principles underpinning the Constant Context Architecture:
Bounded Module Size
Each module's implementation is capped below a maximum token limit (Smax) to ensure both humans and LLMs can parse it in one pass without context overflows.Bounded Interface Size
Public interfaces must remain minimal and self-describing, constrained by an interface token limit (Imax).Limited Dependencies
Each module may directly depend on at most d other modules. This design choice constrains cognitive load and prevents exponential context growth.Locality of Modification
Any change within a module requires a fixed, predictable context: the module's own implementation, its dependencies' interfaces, and a small slice of global metadata.Progressive Expansion
Systems grow primarily by adding new modules, not by inflating existing ones. This ensures no module becomes a sprawling monolith over time.
When these principles are rigorously enforced, the total amount of context required to modify any part of the system remains constant—independent of overall system size.
Context Windows: Practical Considerations
Modern LLMs like Claude and GPT-4 can handle increasingly large contexts (100K-1M+ tokens), yet scaling context length has diminishing returns. Research such as Stanford's "Lost in the Middle" study reveals that as the prompt grows large, models often underutilize or "forget" significant middle portions. Handling bigger prompts also incurs higher computational cost, latency, and bandwidth usage.
Even assuming context windows continue to expand, the constant context architecture retains its advantages:
Reduced Computational Overhead: Small, relevant prompts are cheaper and faster to process.
Predictability: Teams can rely on a bounded approach that doesn't break if context costs spike or if certain LLMs lag in context capabilities.
Stability and Clarity: Modular organization remains a best practice for human comprehension as well, even if an AI can handle bigger chunks of text.
Thus, designing systems to stay within a modest "effective context" helps both current and future AI-driven workflows, even if theoretical maximum context grows.
Examining Retrieval-Augmented Solutions
Retrieval-Augmented Generation (RAG) offers a tempting workaround: the LLM fetches relevant code snippets as needed. This can indeed allow an AI to query large repositories. But RAG has limits when it comes to safe, confident code modifications:
Completeness: RAG-based approaches must ensure all affected dependencies are retrieved before a change—a nontrivial challenge.
Ripple Effects: Even apparently localized changes can have far-reaching implications in tightly coupled systems.
Contextual Understanding: Effective modification often requires not only code snippets but an understanding of architectural conventions, domain constraints, and design intent.
While RAG can help navigate large projects, it's no panacea. The "retrieval paradox" arises when the system must know what it doesn't already know to fetch the right context. By contrast, a constant context system guarantees that any needed information is already contained within a bounded scope—no blind retrieval is necessary.
CCA Formalized
Let:
n = number of modules in the project
M = {m1, m2, …, mn} the set of modules
Size(mi) ≤ Smax (each module's implementation is under a fixed limit)
Interface(mi) ≤ Imax (public interfaces are also bounded)
Each module has at most d direct dependencies
Cmodel = LLM's total context window size
Efactor = effective utilization factor (fraction of the LLM's context truly leveraged, ~0.5 to 0.7 based on empirical studies)
When modifying module mi, the required context is:
C_required = Size(m_i) + d × I_max + G_maxWhere Gmax accommodates global types or metadata. The system enforces:
C_required ≤ E_factor × C_modelThus, even as n → ∞, the context needed to grasp or modify a single module remains constant. This ensures O(1) context requirements for any local change, an enormous advantage for LLM assistance.
Parameters for the Real World
As a starting point:
Smax = 6,000 tokens (~1,500 lines of code). Empirical testing suggests both AI and human comprehension degrade with modules significantly larger than this.
Imax = 800 tokens (~50 method signatures + docs). Limits interface sprawl while maintaining clarity.
d = 5 (maximum direct dependencies). Empirical codebase studies show most well-designed modules rarely exceed this in practice.
Gmax = 1,000 tokens (global architectural metadata).
Cmodel = 100,000 tokens (feasible for advanced models like Claude or GPT-4).
Efactor = 0.6 (common "usable" fraction of context, given diminishing returns).
Hence:
C_required = 6,000 + (5 × 800) + 1,000 = 11,000 tokensOnly ~11% of the total context is consumed, leaving ample overhead for the AI's reasoning. This approach aligns with existing best practices: keep modules relatively small, limit their dependencies, and maintain minimal global coupling.
Strategies for Bringing Existing Codebases into CCA compliance
Many codebases don't start with strict module size or dependency caps. Here's how to refactor effectively:
Assess Module Size
Identify the largest files first. Tools like ESLint, Tokei, or custom scripts can count lines/tokens.
Split modules that exceed Smax into smaller, cohesive submodules. For instance, a "mega report generator" might become three separate classes.
Rework Interfaces
Check your services for huge "God interfaces" full of methods.
Refactor them into multiple narrower interfaces. Keep each ≤ Imax.
Enforce minimal duplication by centralizing shared definitions in well-defined spots.
Limit Dependencies
Chart each module's direct imports. If some file depends on 12 modules, consider a façade or aggregator.
Aim for each module to have ≤ d direct dependencies. This might mean reorganizing utility libraries or grouping closely related logic.
Manage Global Metadata
Corral scattered constants, type definitions, or global configs into a small set of reference files.
Monitor that this doesn't grow beyond Gmax; if it does, break it into domain-specific "globals."
This process can be incremental: you don't have to fix everything at once. Start with frequently changed modules. As you refactor and introduce new features, align them with CCA principles.
Refactoring Patterns for Constant Context Compliance
Transitioning to a constant context model often demands systematic refactoring:
Interface Segregation
If an interface exceeds Imax, break it into multiple focused interfaces.
Module Decomposition
Large modules that approach Smax can be split into coherent submodules, each with a clear responsibility.
Dependency Reduction
If a module depends on more than d neighbors, introduce facades or wrappers to group related services. This reduces direct coupling and enforces the d limit.
These patterns align with established SOLID principles—particularly Interface Segregation, Single Responsibility, and Dependency Inversion—giving your refactoring a robust theoretical foundation.
Adaption over reinvention
This paradigm synthesizes longstanding software tenets:
Information Hiding (Parnas, 1972): Modules should hide internal complexities. Here, we simply add quantitative bounds to keep them comprehensible.
Domain-Driven Design (Eric Evans): Bounded Contexts provide semantic boundaries, which can map directly to constant context modules. This pairs nicely with CCA.
Interface Segregation (SOLID): Minimizing interface size is crucial to preventing "API bloat" that drags in unnecessary complexities.
Law of Demeter: "Talk only to your immediate friends." The d dependency cap is essentially a formal version of this principle.
By merging these with the constraints of LLM context windows, we obtain a modern architecture tailored for AI-human collaboration.
Module-Oriented Testing
CCA brings significant advantages for testing—a benefit we haven't yet explored:
Bounded Test Scope: When modules have clear, limited responsibilities and interfaces, tests become naturally focused. Each test suite targets one module's functionality, without sprawling dependencies.
Predictable Test Coverage: With bounded module size, achieving high test coverage becomes more feasible. You can exhaustively test a 300-line module far more easily than a 3,000-line behemoth.
Isolated Test Execution: CCA's dependency constraints enable better test isolation. Since each module depends on at most d other modules, mocking dependencies is manageable—you'll never need to mock dozens of interconnected services.
AI-Assisted Test Generation: LLMs excel at generating tests for well-bounded modules. By keeping each module within the context window, AI can understand its functionality completely and generate comprehensive test cases.
Test Locality: When a module changes, only its own tests and possibly those of its immediate dependents need re-evaluation. This "O(1) test impact" parallels the O(1) comprehension benefit.
A practical approach combines these benefits:
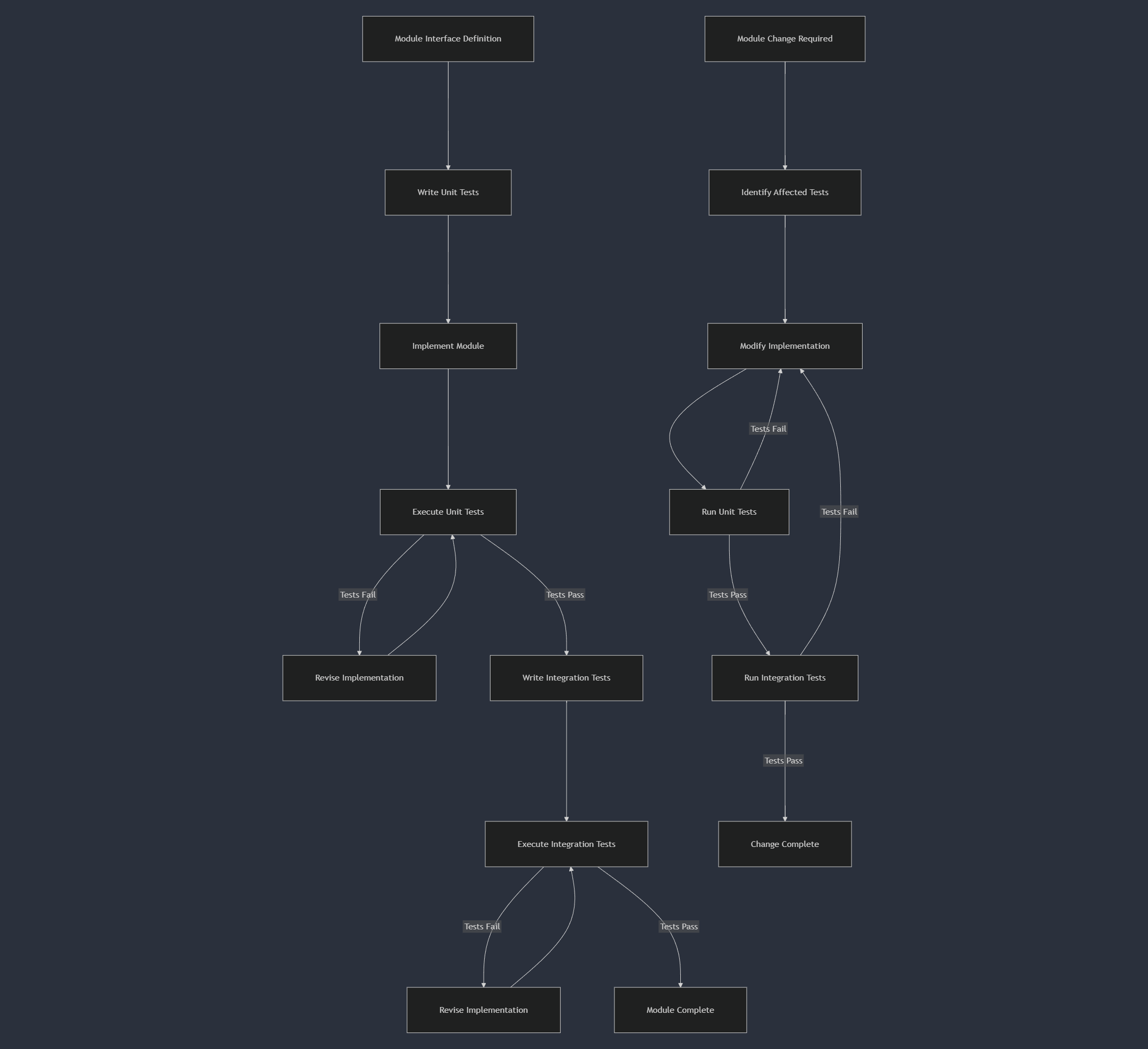
In CCA, testing becomes more predictable, more manageable, and more effective—another reason why bounded modules benefit both human developers and AI assistants.
Example LLM Prompt for Module Change
Here's a realistic prompt showing how CCA principles enable effective AI-augmented development:
0. REQUIREMENTS
I need to implement weighted normalization that allows each value to have a weight associated with it. The weights should be provided as an optional parameter called 'weights' in the TransformerConfig, mapping column names to weight values (all 1.0 by default). The weighted mean and stdDev calculations should account for these weights.
Can you update the NormalizationTransformer implementation to support this feature? Make sure it handles edge cases gracefully.
1. CURRENT MODULE IMPLEMENTATION:
"""
// transformations/normalization.ts
import { DataBatch, ColumnStats, TransformerConfig } from '../types';
import { MathUtils } from '../utils/math';
import { LoggingService } from '../services/logging';
import { ConfigManager } from '../config';
import { MetricsCollector } from '../telemetry';
export class NormalizationTransformer {
private columns: string[];
private addSuffix: boolean;
private logger: LoggingService;
private metrics: MetricsCollector;
constructor(config: TransformerConfig) {
this.columns = config.columns || [];
this.addSuffix = config.addSuffix || false;
this.logger = new LoggingService('normalization');
this.metrics = new MetricsCollector('normalization');
}
public transform(batch: DataBatch): DataBatch {
this.logger.info('Starting normalization', { columns: this.columns });
this.metrics.incrementCounter('batches_processed');
if (!batch || !batch.data || batch.data.length === 0) {
this.logger.warn('Empty batch received');
return batch;
}
// Calculate statistics for each column
const stats: Record<string, ColumnStats> = {};
for (const column of this.columns) {
if (!batch.schema.includes(column)) {
this.logger.warn(`Column not found in schema: ${column}`);
continue;
}
const values = batch.data.map(row => row[column]).filter(v => v != null);
if (values.length === 0) {
this.logger.warn(`No valid values for column: ${column}`);
continue;
}
stats[column] = {
mean: MathUtils.mean(values),
stdDev: MathUtils.stdDev(values),
min: Math.min(...values),
max: Math.max(...values)
};
this.logger.debug(`Statistics for ${column}`, stats[column]);
}
// Apply normalization
const result = {
schema: [...batch.schema],
data: [...batch.data]
};
for (const column of this.columns) {
if (!stats[column]) continue;
const columnStats = stats[column];
const outputColumn = this.addSuffix ? `${column}_normalized` : column;
if (this.addSuffix && !result.schema.includes(outputColumn)) {
result.schema.push(outputColumn);
}
for (let i = 0; i < result.data.length; i++) {
const row = result.data[i];
const value = row[column];
if (value == null) continue;
// Z-score normalization
const normalizedValue = (value - columnStats.mean) / columnStats.stdDev;
row[outputColumn] = normalizedValue;
}
this.metrics.recordHistogram(`normalized_values_${column}`,
result.data.map(row => row[outputColumn]).filter(v => v != null)
);
}
this.logger.info('Normalization complete', {
inputRows: batch.data.length,
outputRows: result.data.length
});
return result;
}
}
"""
2. DEPENDENCY INTERFACES:
"""
// types.ts
export interface DataBatch {
schema: string[];
data: Record<string, any>[];
}
export interface ColumnStats {
mean: number;
stdDev: number;
min: number;
max: number;
}
export interface TransformerConfig {
columns?: string[];
addSuffix?: boolean;
}
"""
"""
// utils/math.ts
export class MathUtils {
static mean(values: number[]): number {
if (values.length === 0) return 0;
return values.reduce((sum, val) => sum + val, 0) / values.length;
}
static stdDev(values: number[]): number {
if (values.length <= 1) return 0;
const avg = MathUtils.mean(values);
const squareDiffs = values.map(value => Math.pow(value - avg, 2));
return Math.sqrt(MathUtils.mean(squareDiffs));
}
}
"""
"""
// services/logging.ts
export class LoggingService {
constructor(private context: string) {}
public info(message: string, data?: any): void {}
public warn(message: string, data?: any): void {}
public error(message: string, data?: any): void {}
public debug(message: string, data?: any): void {}
}
"""
"""
// config.ts
export class ConfigManager {
static getConfig(name: string): any {
// Implementation details hidden
return {};
}
}
"""
"""
// telemetry.ts
export class MetricsCollector {
constructor(private context: string) {}
public incrementCounter(name: string): void {}
public recordHistogram(name: string, values: number[]): void {}
}
"""
3. GLOBAL METADATA:
"""
// Project context: Data processing pipeline for financial analytics
// Architecture pattern: Bounded modules with typed interfaces
// Global naming conventions:
// - Services end with 'Service'
// - Utilities end with 'Utils'
// - Transformers operate on DataBatch objects
// - All public methods are documented with JSDoc
// Debugging: To enable debug logs, set DEBUG=true in environment
// Feature flags:
const FEATURES = {
ENABLE_WEIGHTED_NORMALIZATION: true, // New feature
USE_OPTIMIZED_MATH: false,
COLLECT_DETAILED_METRICS: true
};
// Error codes:
const ERROR_CODES = {
INVALID_BATCH: 'E001',
MISSING_COLUMN: 'E002',
CALCULATION_ERROR: 'E003'
};
"""
This prompt contains everything needed to make the change:
The module's implementation (≤ Smax)
Interfaces of all dependencies (≤ d × Imax)
Global metadata (≤ Gmax)
The total context is only ~1,300 tokens—well within the effective utilization of a typical LLM, leaving ample room for generating a quality response. The AI can fully understand both the implementation and the required change without needing to comprehend the entire codebase.
Future proofing
As LLM inference and networking costs shrink, coherent context limitations grow, and industry tooling improves, you may want to fit more context into a given prompt without rearchitecting your software. Well, your context is also modular!
Imagine your CCA-based system consists of modules MA, MB, MC, etc., each under Smax tokens, with minimal interfaces. You need to modify MA so it interacts more intelligently with MB.
Base Prompt
Under the original (smaller) context environment, you’d typically feed just MA plus the interface definition of MB, along with any relevant global metadata. That suffices for local changes, abiding by strict CCA rules.Expanding the Scope
Now suppose your LLM context capacity has doubled, making it feasible to consider the full implementations of MA and MB. With CCA, this is trivial. You simply add MB’s code to the same prompt. Because each module is self-contained, you’re confident you aren’t accidentally pulling in an unwieldy portion of the system. You can do so for MC as well, if it’s directly relevant and the prompt window allows.Seamless AI Interaction
The AI can now refactor MA in direct awareness of MB’s internals—something it previously treated as a black box behind an interface. This deeper cross-module optimization can yield higher-quality or more integrated changes while preserving the same basic boundaries that prevent scope creep.
With automated tooling, this process is a configuration change away, if not dynamically determined based on your LLM's context limits.
Key Metrics to Track
Context Compliance Ratio: Percentage of modules meeting size & dependency bounds
Context Size Distribution: Statistical distribution of actual module sizes
Modification Efficiency: Comparative time/effort for changes in compliant vs. non-compliant modules
AI Assistance Success Rate: How often AI-proposed changes pass review in compliant vs. non-compliant areas
Developer Satisfaction: Qualitative feedback on navigating and modifying constant context modules
A measured, incremental approach helps prove the model's value before scaling it organization-wide.
Should I use this?
Why invest in this architectural discipline?
Immediate Relevance: If your application already exceeds what an LLM can reliably process in one go, a constant context strategy is immediately advantageous.
Modification Patterns: Systems with frequent, shallow changes across many modules benefit most from local, O(1) comprehensibility.
Team Structure Impact: Distributed teams or those with high turnover see large gains from reduced cognitive overhead.
Compliance Burden: There are real costs to enforcing modular boundaries, but they're offset if AI-augmented tasks become faster and more reliable.
Ultimately, it comes down to: Does your system's size or complexity exceed your AI's (and your developers') effective context limit? If yes, bounding module size and coupling is a direct path to higher productivity and fewer mistakes.
Conclusion
Constant Context Architecture (CCA) is about preserving the benefits of modular design while explicitly accommodating the limitations—and strengths—of AI coding assistants. By capping module size, interface scope, and direct dependencies, you ensure:
A local change never explodes into an unbounded context requirement.
Both human developers and AI tools can stay fully oriented in any module.
Your system remains maintainable by default despite growth.
We are witnessing an architectural moment reminiscent of the shift to object-oriented or domain-driven paradigms. Then, we adapted code to human cognitive patterns; now, we must tailor it to a hybrid environment where both humans and AI collaborate.
As David Parnas once noted, "The best designs result from managing complexity through modular separation." Now, that complexity management also serves a new collaborator: the AI. Systems that embed these constraints will see compounding advantages in agility, reliability, and code quality—both for humans and for the automated agents increasingly shaping our software.
Next Up
I am working on tooling to help teams automate the collection of module context for CCA-compliant codebases, among other things. I plan to share more here soon but reach out if you're interested in contributing or acting as a design partner the meantime: neohalcyon@substack.com